
Stop Sitting on a Pile of Logs: A Practical Guide to Datadog Log Retention

Over the past few years, Datadog has introduced many strategies for log storage, but it’s pretty rare that we see many of these used effectively. Starting in 2018, Datadog introduced Logging Without Limits, allowing users of the platform to firehose their logs into the account and only keep what was needed. The significant benefit wasn’t just the reduction in configuration required to send logs, but also that the logs that are excluded are still processed so custom metrics could still be generated from them.
However - this blog isn’t about the logs you don’t want to keep, it’s about the logs you do want to keep. There’s a few additional facilities that can help us with solid log retention strategies. In addition to standard log indexes, we now also have Datadog Flex Logs, Flex Frozen, the SIEM, and Datadog Log Archives.
At NoBS, we help teams put these capabilities to work—simplifying Datadog setup, retention, and cost optimization so engineers get practical, scalable observability without the fluff.
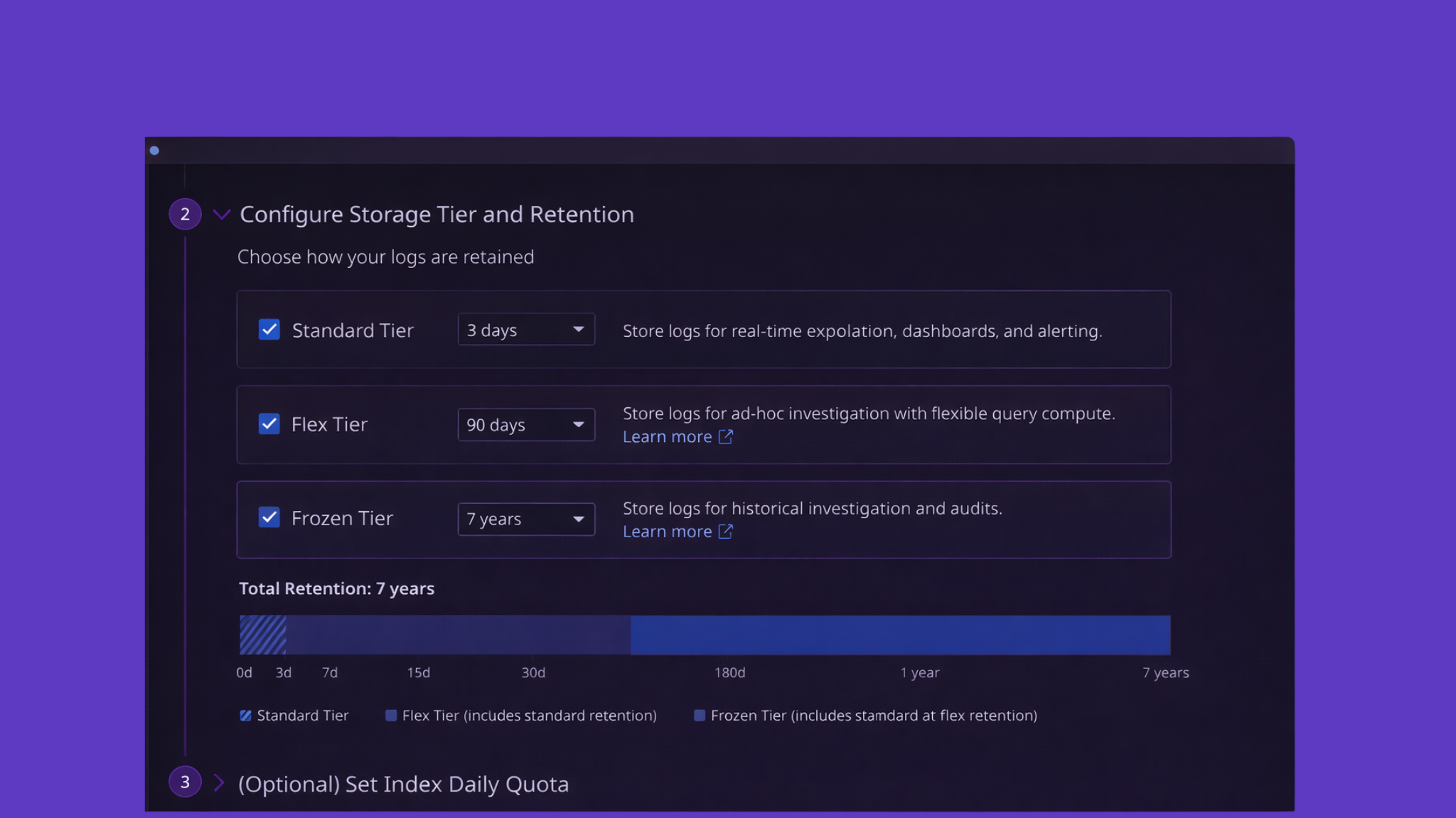
Getting that right starts with the basics, so let’s keep it simple to start. Datadog standard indexes allow for 3, 7, 15, 30, 45, and 60 days, with the default main index being 15 days. Given that log indexes are ordered and a log will be dropped into the first index with a matching query, we can create a very simple example of log tiering. It’s not uncommon to see engineers wanting to keep DEBUG level logs for troubleshooting, but these are typically extremely high volume and therefore a higher cost, and it’s likely that we don’t need them kept around forever. Since pricing of log indexing is based on the retention period, we can significantly reduce cost and maintain value by having an index set to 3 day retention for status:DEBUG followed by the main default index, like so:
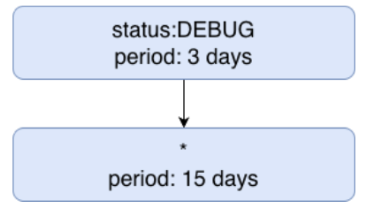
This same strategy applies to other retention periods as well, but make sure your ordering is correct! If there was another index present below the wildcard index, not a single log would ever make it into that index.
It should be noted that various log indexes are used for different retention periods, and not necessarily for the logical separation of data. Unlike other tools you may be familiar with like Splunk or Elasticsearch, Datadog log queries (by default) will query all indexes so the actual indexing of the data is otherwise irrelevant to the user querying it. However, if you chose to use RBAC roles to restrict access to data, the most straightforward way to do that would be to filter the sensitive data into an index, and put the restriction on the query index:my-sensitive-index.
Moving on to Flex Logs - this can be a cost effective way to store a lot of logs, and users have the ability to log directly to Flex Logs, or to flush to Flex after the initial standard indexing retention. The biggest tradeoff here is that you cannot create alerts against Flex Logs, although they can be queried in the log explorer and on dashboards as you would expect. If you don’t need to alert on your logs and just need them for the enriched information they provide, logging directly into Flex Logs might work for you. Despite the alerting part, they still run through all of the rest of the log processing, so custom metrics can be made if you do need to alert off of logs sent directly into Flex (just be careful of your cardinality here ;) ). Expanding on the above, lets say we wanted to keep DEBUG logs for longer, be able to alert on the main index, and then flush the main index to Flex after 15 days. It would look something like this:
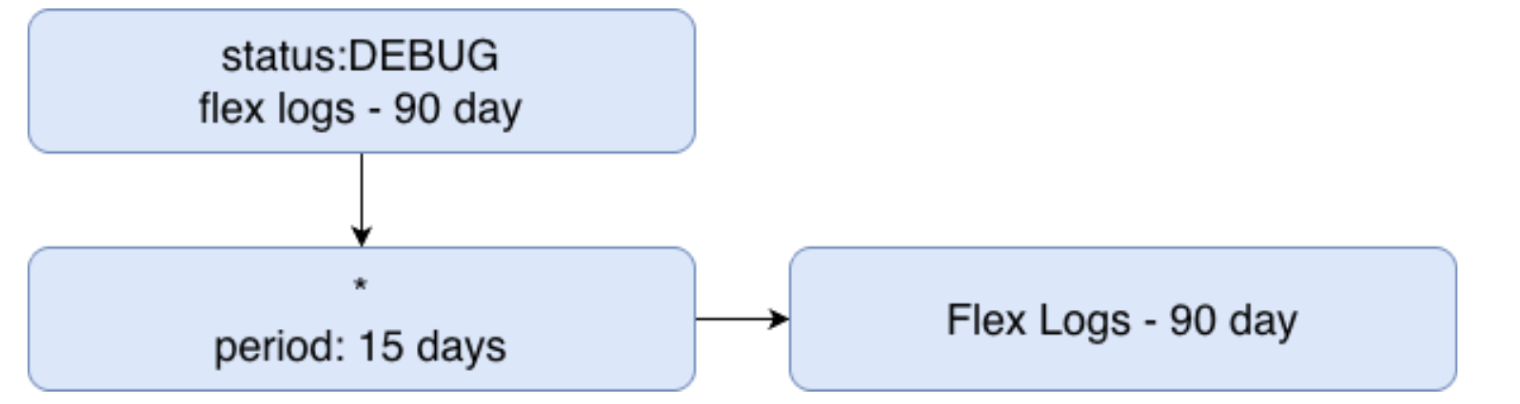
While Flex Logs can be stored for up to 15 months, do you find that this is still not enough time for you? Well, you have 2 other options. At DASH 2025, Datadog announced the new Flex Frozen tier, allowing for up to 7 years of retention. Flex Frozen is still in private preview, but will be generally available at some point in the future.
Do you need longer term storage right now? Datadog also offers Log Archiving to external cloud providers like AWS S3, Azure Blob, and Google Cloud Storage. With this archiving, logs are shipped to your external destination as they are ingested to Datadog. So unlike Flex logs, your logs aren’t flushed to archive after expiring out of an indexing tier, they are sent there immediately after the rest of the processing pipeline. The really nice part about the archiving being immediate is that you can still archive logs that are not indexed, and rehydrate them if you need them for investigation at a later point in time. When you rehydrate, you’ll select the archive, timespan, and query you want to execute, and logs from that archive will be reindexed at the point in time the log happened. So that hour of logs you need from 6 months ago will show up on the timeline at the same time they were created, keeping them relative to their actual point in time, not as newly indexed logs. The other beautiful part of archives is that your retention period is up to you - you control the bucket, so you control your retention.
Last but not least is the SIEM index. This is a special index where logs are retained for 450 days and available for analysis with features like Impossible Travel or Content Anomalies. So if you feel like you’ve finally had it with Splunk, take a look at the Datadog SIEM. Just like the other indexes, this can still be queried transparently through the Log Explorer; you aren’t pinned to just the SIEM.
Let’s tie this all together in one big logging strategy.
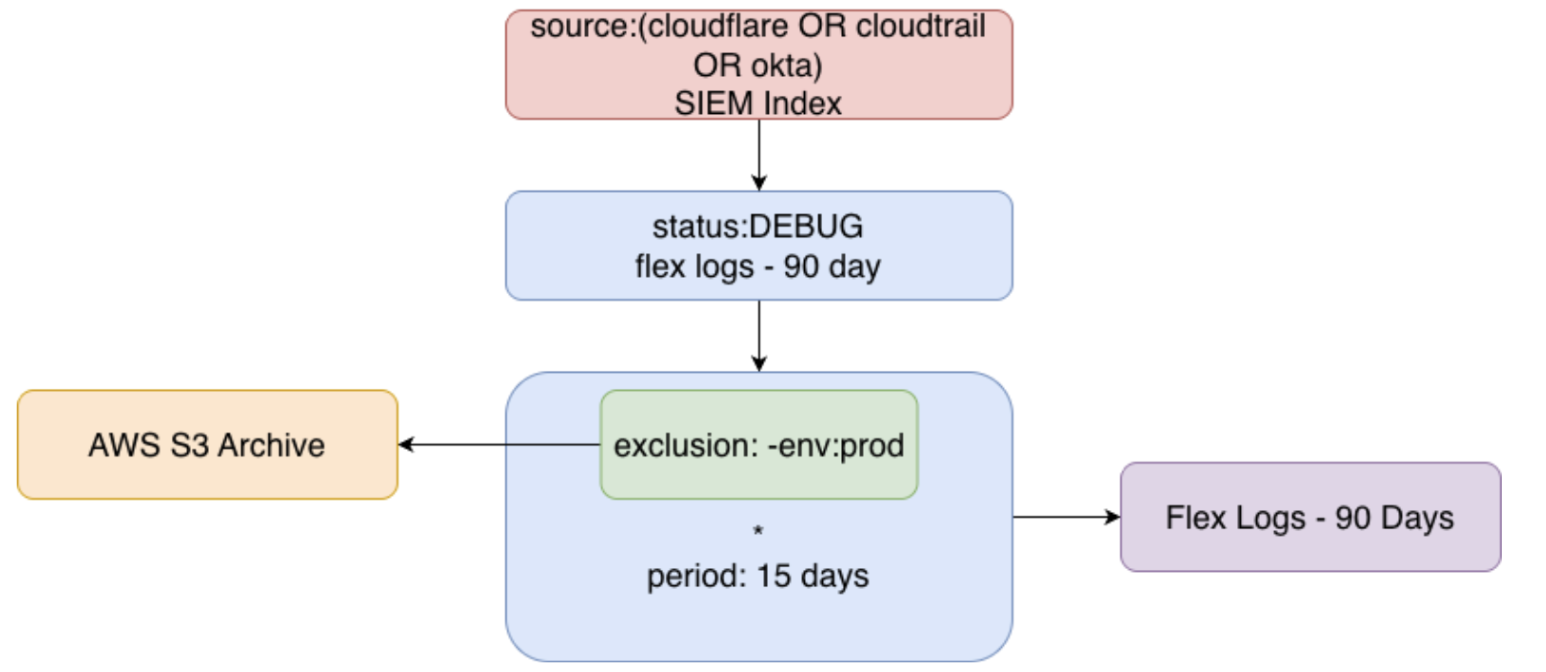
If you’re using the SIEM, this should always be first in the indexing order. Security is important - you don’t want some of these logs falling into other buckets by accident. If that query isn’t matched, we’ll hit the next index. If it’s a DEBUG level log? Straight to Flex Logs. Anything else goes into the main index. If it’s a non-prod environment, we can exclude that from indexing and send it to the archive - just in case. Once the logs collected in main expire after 15 days, off to Flex it goes for another 90.
Hopefully this helps you think a bit more about your logging strategy. While this blog post really just scratches the surface and there is so much more that is possible, at least we have a good understanding of some of our options now. Do you need some help with getting beyond the surface level?
Get in touch with NoBS or email - sales@nobs.tech
FAQ: Datadog Log Retention (NoBS)
Last updated: 2025-10-24
What’s the right order for Datadog log indexes?
Put the most specific, highest-value buckets first; catch-alls last. Datadog routes each log to the first match—order controls cost and retention.
Should DEBUG logs be kept, and for how long?
Keep them short and cheap. Common pattern: a 3-day DEBUG index (or send DEBUG straight to Flex if alerts aren’t needed); let everything else hit the main index.
Flex Logs vs. standard indexes—when to use which?
Use standard indexes when you need alerting on live data; use Flex for cheaper, searchable history when alerts aren’t required on that tier.
Can I alert on Flex Logs?
Not directly. Flex supports queries/dashboards, not alerts. If alerting is required, emit a derived metric during processing or alert while data is in a standard index.
When should I use Log Archives instead of Flex?
Pick Archives for the cheapest long-term storage/compliance. Logs ship to your bucket immediately at ingest (even if not indexed) and can be rehydrated later.